Title
El paquete RODBC conecta R con Ms Access. Con él podremos acceder a tablas y consultas ya creadas en Access: leer, guardar, copiar y manipular datos de tablas y consultas. El paquete emplea la conectividad ODBC (Open Database Connectivity) para establecer la conexión con Ms Access y mediante SQL (Structured Query Language) se interactúa con la base de datos.
Conexión de R con Ms Access
Instalamos y cargamos el paquete RODBC
install.packages("RODBC")
library(RODBC)
# Listado de DSNs disponibles
odbcDataSources()
Excel Files
"Microsoft Excel Driver (*.xls, *.xlsx, *.xlsm, *.xlsb)"
MS Access Database
"Microsoft Access Driver (*.mdb, *.accdb)"
Establecemos la conexión, el canal. Emplearemos como ejemplo la base de datos
Neptuno.mdb
# Interactivamente
canal <- odbcConnectAccess(file.choose())
# Escribiendo la ruta
neptuno <- "C:/Users/User1/Documents/R/Neptuno.mdb" # Ruta correspondiente
canal <- odbcConnectAccess(neptuno)
# Base de datos en el directorio de trabajo
canal <- odbcConnectAccess("Neptuno.mdb")
# Descargando el fichero zip
# en el directorio de trabajo
url <- "https://sites.google.com/site/nubededatosblogspotcom/Neptuno.zip"
download.file(url, "Neptuno")
unzip("Neptuno")
canal <- odbcConnectAccess("Neptuno.mdb")
# Descargando el fichero zip
# en un archivo temporal
temp <- tempfile()
download.file("https://sites.google.com/site/nubededatosblogspotcom/Neptuno.zip", temp)
unzip(temp)
unlink(temp)
canal <- odbcConnectAccess("Neptuno.mdb")
Detalles de la conexión
canal
RODBC Connection 1
Details:
case=nochange
DBQ=C:\Users\User1\Documents\R\Neptuno.mdb
Driver={Microsoft Access Driver (*.mdb)}
DriverId=25
FIL=MS Access
MaxBufferSize=2048
PageTimeout=5
UID=admin
Listado de tablas y consultas
Devuelve un data frame de las tablas y consultas accesibles desde la conexión ODBC establecida. Está compuesto de cinco columnas: catalog, schema, name, type and remarks. Incluye las tablas del sistema por defecto.
sqlTables(canal)
TABLE_CAT TABLE_SCHEM TABLE_NAME TABLE_TYPE REMARKS
1 C:\\R\\Neptuno <NA> MSysAccessObjects SYSTEM TABLE <NA>
2 C:\\R\\Neptuno <NA> MSysAccessXML SYSTEM TABLE <NA>
3 C:\\R\\Neptuno <NA> MSysACEs SYSTEM TABLE <NA>
4 C:\\R\\Neptuno <NA> MSysCmdbars SYSTEM TABLE <NA>
5 C:\\R\\Neptuno <NA> MSysIMEXColumns SYSTEM TABLE <NA>
6 C:\\R\\Neptuno <NA> MSysIMEXSpecs SYSTEM TABLE <NA>
Para obtener una columna específica, empleamos el símbolo $ seguido del nombre de la columna.
sqlTables(canal)$TABLE_NAME # All objects' names
Especificamos el argumento
tableType para elegir, tablas del sistema, tablas o consultas.
# Tablas del sistema
sqlTables(canal, tableType = "SYSTEM TABLE")$TABLE_NAME
[1] "MSysAccessObjects" "MSysAccessXML"
[3] "MSysACEs" "MSysCmdbars"
[5] "MSysIMEXColumns" "MSysIMEXSpecs"
[7] "MSysNameMap" "MSysNavPaneGroupCategories"
[9] "MSysNavPaneGroups" "MSysNavPaneGroupToObjects"
[11] "MSysNavPaneObjectIDs" "MSysObjects"
[13] "MSysQueries" "MSysRelationships"
# Tablas
sqlTables(canal, tableType = "TABLE")$TABLE_NAME
[1] "Categorías" "Clientes" "Compañías de envíos"
[4] "Detalles de pedidos" "Empleados" "Pedidos"
[7] "Productos" "Proveedores"
# Consultas
sqlTables(canal, tableType = "VIEW")$TABLE_NAME
[1] "Clientes y proveedores por ciudad"
[2] "Consulta de pedidos"
[3] "Detalle de pedidos con descuento"
[4] "Facturas"
[5] "Filtro facturas"
[6] "Lista alfabética de productos"
Estructura de las columnas
Devuelve un data frame con la información de las columnas de las tablas o consultas de la conexión establecida (canal).
[1] "TABLE_CAT" "TABLE_SCHEM"
[3] "TABLE_NAME" "COLUMN_NAME"
[5] "DATA_TYPE" "TYPE_NAME"
[7] "COLUMN_SIZE" "BUFFER_LENGTH"
[9] "DECIMAL_DIGITS" "NUM_PREC_RADIX"
[11] "NULLABLE" "REMARKS"
[13] "COLUMN_DEF" "SQL_DATA_TYPE"
[15] "SQL_DATETIME_SUB" "CHAR_OCTET_LENGTH"
[17] "ORDINAL_POSITION" "IS_NULLABLE"
[19] "ORDINAL"
Para obtener una columna específica, empleamos el símbolo $ seguido del nombre de la columna.
sqlColumns(canal, "Clientes")$COLUMN_NAME
[1] "IdCliente" "NombreCompañía" "NombreContacto"
[4] "CargoContacto" "Dirección" "Ciudad"
[7] "Región" "CódPostal" "País"
[10] "Teléfono" "Fax"
Manipulación de datos
Antes de manipular datos es recomendable hacer una copia de seguridad. Las funciones sqlUpdate y sqlDrop ocasionan cambios o pérdidas de datos irreversibles.
Tenemos dos opciones:
- sqlFetch tanto para tablas como consultas ya existentes.
ConsultaDePedidos <- sqlFetch(canal, sqtable = "Detalles de pedidos")
# Para limitar el nº de filas importadas: max
ConsultaDePedidos <- sqlFetch(canal, sqtable = "Detalles de pedidos", max = 100)
- sqlQuery para enviar consultas SQL a la base de datos de Ms Access. Se puede incluir cualquier sentencia válida de SQL, incluyendo la creación, modificación, actualización o selección.
Clientes <- sqlQuery(canal, "SELECT * FROM Clientes")
# Para limitar el nº de filas leídas: max
Clientes <- sqlQuery(canal, "SELECT * FROM Clientes", max = 10)
Para evitar errores cuando el nombre de las tablas o consultas incluyen espacios en blanco, los escribimos entre corchetes.
ConsultaDePedidos <- sqlQuery(canal, "SELECT * FROM [Consulta de pedidos]")
Una consulta más compleja, Facturas de la Neptuno.mdb, copiando el código directamente SQL. Sustituimos las comillas dobles " " por simples ' '[Nombre] & ' ' & [Apellidos] para evitar el error: Error: unexpected string constant.
Facturas <- sqlQuery(canal, "SELECT Pedidos.Destinatario, Pedidos.DirecciónDestinatario, Pedidos.CiudadDestinatario, Pedidos.RegiónDestinatario, Pedidos.CódPostalDestinatario, Pedidos.PaísDestinatario, Pedidos.IdCliente, Clientes.NombreCompañía, Clientes.Dirección, Clientes.Ciudad, Clientes.Región, Clientes.CódPostal, Clientes.País, [Nombre] & ' ' & [Apellidos] AS Vendedor, Pedidos.IdPedido, Pedidos.FechaPedido, Pedidos.FechaEntrega, Pedidos.FechaEnvío, [Compañías de envíos].NombreCompañía, [Detalles de pedidos].IdProducto, Productos.NombreProducto, [Detalles de pedidos].PrecioUnidad, [Detalles de pedidos].Cantidad, [Detalles de pedidos].Descuento, CCur([Detalles de pedidos].PrecioUnidad*[Cantidad]*(1-[Descuento])/100)*100 AS PrecioConDescuento, Pedidos.Cargo
FROM Productos INNER JOIN ((Empleados INNER JOIN ([Compañías de envíos] INNER JOIN (Clientes INNER JOIN Pedidos ON Clientes.IdCliente = Pedidos.IdCliente) ON [Compañías de envíos].IdCompañíaEnvíos = Pedidos.FormaEnvío) ON Empleados.IdEmpleado = Pedidos.IdEmpleado) INNER JOIN [Detalles de pedidos] ON Pedidos.IdPedido = [Detalles de pedidos].IdPedido) ON Productos.IdProducto = [Detalles de pedidos].IdProducto")
Source: local data frame [2,155 x 26]
Destinatario DirecciónDestinatario CiudadDestinatario
1 Wilman Kala Keskuskatu 45 Helsinki
2 Wilman Kala Keskuskatu 45 Helsinki
3 Wilman Kala Keskuskatu 45 Helsinki
4 Toms Spezialitäten Luisenstr. 48 Münster
5 Toms Spezialitäten Luisenstr. 48 Münster
6 Hanari Carnes Rua do Paço, 67 Río de Janeiro
7 Hanari Carnes Rua do Paço, 67 Río de Janeiro
8 Hanari Carnes Rua do Paço, 67 Río de Janeiro
9 Victuailles en stock 2, rue du Commerce Lyon
10 Victuailles en stock 2, rue du Commerce Lyon
.. ... ... ...
Variables not shown: RegiónDestinatario (fctr), CódPostalDestinatario (fctr), PaísDestinatario (fctr), IdCliente (fctr), NombreCompañía (fctr), Dirección (fctr), Ciudad (fctr), Región (fctr), CódPostal (fctr), País (fctr), Vendedor (fctr), IdPedido (int), FechaPedido (time), FechaEntrega (time), FechaEnvío (time), NombreCompañía.1 (fctr), IdProducto (int), NombreProducto (fctr), PrecioUnidad (dbl), Cantidad (int), Descuento (dbl), PrecioConDescuento (dbl), Cargo (dbl)
Para crear una tabla en Access a partir de un data frame utilizamos la función sqlSave. Los principales argumentos son:
channel - conexión creada con odbcConnect.
dat - data frame.
tablename - nombre de la tabla creada, por defecto el del data frame.
rownames - valor lógico (TRUE o FALSE) o el nombre de la columna de los nombres de de fila.
addPK - valor lógico, para establecer los rownames (nombres de fila) como clave principal.
# Nombre de la nueva tabla el del data frame
sqlSave(canal, women, rownames = FALSE)
# Especificando el nombre de la nueva tabla
sqlSave(canal, women, "mujeres", rownames = FALSE)
# filas (rownames) como clave principal
sqlSave(canal, women, "mujeres", rownames = "filas", addPK = TRUE)
sqlUpdate actualiza la tabla siempre que las filas ya existan. Si no, generará un error: [RODBC] Failed exec in Update. Los principales argumentos son:
channel - conexión creada con odbcConnect.
dat - data frame.
tablename - nombre de la tabla creada, por defecto el del data frame.
index - columna que empleará como clave principal, común al da
addPK - valor lógico, para establecer los rownames (nombres de fila) como clave principal.
Ejemplo 1
# Tabla con clave principal filas
sqlSave(canal, women, "mujeres", rownames = "filas", addPK = TRUE)
# La columna filas es un campo de texto (VARCHAR)
sqlColumns(canal, "mujeres")[c(4, 6)]
COLUMN_NAME TYPE_NAME
1 filas VARCHAR
2 height DOUBLE
3 weight DOUBLE
Datos originales:
sqlFetch(canal, "mujeres", max = 6)
filas height weight
1 1 58 115
2 2 59 117
3 3 60 120
4 4 61 123
5 5 62 126
6 6 63 129
# Data frame act con los registros a actualizar
# Por ser filas un campo de texto
# en la tabla mujeres as.character
filas <- as.character(c(1, 2, 3))
height <- c(70, 75, 80)
weight <- c(120, 125, 130)
act <- data.frame(filas, height, weight)
# Actualizamos usando filas como index
sqlUpdate(canal, act, "mujeres", index = "filas")
Datos actualizados:
sqlFetch(canal, "mujeres", max = 6)
filas height weight
1 1 70 120
2 2 75 125
3 3 80 130
4 4 61 123
5 5 62 126
6 6 63 129
Ejemplo 2
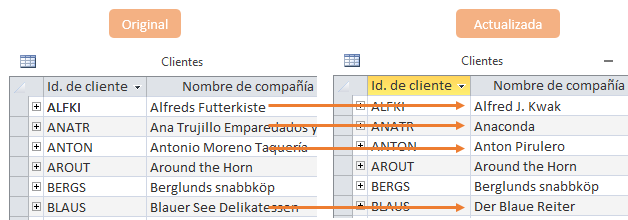
Otro ejemplo actualizando la tabla Clientes de Neptuno.
# Data frame act con los registros a actualizar
IdCliente <- c("ALFKI", "BLAUS", "ANATR", "ANTON")
NombreCompañía <- c("Alfred J. Kwak", "Der Blaue Reiter",
"Anaconda","Anton Pirulero")
act <- data.frame(IdCliente, NombreCompañía)
# Actualización usando la clave principal IdCliente
sqlUpdate(canal, act, "Clientes", index = "IdCliente")
IdCliente NombreCompañía
1 ALFKI Alfred J. Kwak
2 ANATR Anaconda
3 ANTON Anton Pirulero
4 AROUT Around the Horn
5 BERGS Berglunds snabbköp
6 BLAUS Der Blaue Reiter
Eliminación de tablas
Para eliminar tablas o consultas de la base de datos empleamos la función sqlDrop. Cuidado pues la acción es irreversible.
sqlDrop(channel = canal, "women")
Referencias


















 Nube de datos
Nube de datos