Title
Con R podemos leer tablas HTML dentro de un documento HTML. Como ejemplo vamos a la leer la siguiente tabla con las
250 películas más votadas en la imdb.
Importación
Para importar tablas HTML con R necesitamos instalar el paquete XML pensado para leer y crear documentos XML y HTML.
Usamos la función readHTMLTable cuyos argumentos fundamentales son:
url
which: el número de tabla del documento HTML
stringsAsFactors = FALSE para evitar que convierta los caracteres en factores.
library(XML)
url <- "http://www.imdb.com/chart/top"
peliculas <- readHTMLTable(url, which = 1, stringsAsFactors = FALSE)
Una vez creado el data frame películas, podemos usar las siguientes funciones para inspeccionarlo, editarlo y ver sus propiedades.
head(peliculas) # 6 primeras filas
tail(peliculas) # 6 últimas filas
edit(peliculas) # Abrir en editor de texto
fix(peliculas) # Editar el objeto
dim(peliculas) # Nº filas y columnas
names(peliculas) # Nombre de las columnas
str(peliculas) # Propiedades
Manipulación
En la imagen anterior vemos que tenemos un problema con los datos importados. La primera y la última columna están en blanco. La segunda contiene la posición (rank), el título (title) y el año (year). La valoración (rating) es un vector de caracteres en lugar de numérico. Varias columnas incluyen \n.
El primer problema que vamos a atacar es dividir la segunda columna en tres: rank, title y year. Para ello empleamos la función colsplit del paquete reshape2.
library(reshape2) # Para usar la función colsplit
peliculas <- transform(peliculas, peliculas = colsplit(peliculas[[2]], pattern = "\n", names = c('rank', 'title', 'year')))
Eliminamos las columnas sobrantes y redundantes y les asignamos nuevos nombres.
peliculas[, c(1,2,4,5,6)] <- list(NULL)
colnames(peliculas) <- c("rating", "title", "year")
Aún así seguimos teniendo algunos problemas por resolver. El rating es una vector de caracteres no un vector numérico. En title hay espacios delante y detrás de los títulos. En year los años están entre paréntesis, con espacios delante y detrás, y es un vector de caracteres. Además, las columnas están desordenadas.
peliculas$title <- gsub("^ +|+ $", "", peliculas$title)
peliculas$year <- gsub("[[:punct:]]|[[:space:]]", "", peliculas$year)
peliculas$rating <- as.numeric(peliculas$rating)
peliculas$year <- as.integer(peliculas$year)
peliculas <- peliculas[c(2,3,1)] # Ordena columnas
Gráficos
Representamos los datos para poder ver en que años se concentran las películas mejor valoradas. Empleamos el paquete estándar graphics cargado por defecto. En otra entrada creamos los gráficos con ggplot2.
# Gráficos muy sencillos
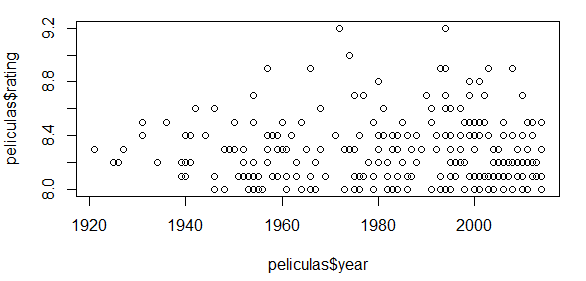
plot(x = peliculas$year, y = peliculas$rating) # Gráfico de dispersión
hist(peliculas$year) # Histograma
Con el siguiente diagrama de dispersión se aprecia la concentración de películas en las últimas décadas.
Con el histograma contamos el número de películas dentro de cada década.
Refinamos y personalizamos el histograma para conocer exactamente el número de películas por década.
# Gráfico personalizado
intervalos <- seq(1920, 2020, 10)
hist(peliculas$year,
breaks = intervalos,
right = FALSE,
col = "steelblue",
border = "white",
labels = TRUE,
main = "nº de películas",
xaxt = "n",
yaxt = "n",
xlab = "Año",
ylab = NULL,
ylim = c(0, 60))
axis(side = 1, at = intervalos)
Para ver gráficos similares generados con el paquete ggplot2 visita
esta entrada.
Tabla de frecuencias
Si en lugar de explorar visualmente, creamos directamente una tabla de frecuencias.
intervalos <- seq(1920, 2020, 10)
frecuencias <- cut(peliculas$year,
breaks = intervalos,
dig.lab = 4, # Nº de dígitos de los intervalos
right = FALSE) # Intervalos [a, b). Por defecto: (a, b]
tabla.frec <- table(frecuencias) # Crea la tabla de frecuencias
as.data.frame(tabla.frec)
# Tabla de frecuencias
frecuencias Freq
1 [1920,1930) 4
2 [1930,1940) 7
3 [1940,1950) 15
4 [1950,1960) 30
5 [1960,1970) 21
6 [1970,1980) 21
7 [1980,1990) 30
8 [1990,2000) 43
9 [2000,2010) 54
10 [2010,2020) 25
Observaciones
Suponiendo un nivel de cantidad y calidad constante, esperaríamos unas 25 películas por década. Sin embargo, las películas más recientes están excesivamente representadas. Aún queda la mitad de la década de 2010-2020 y ya hay 25 películas dentro de las 250 mejores.
Posibles factores:
- La cantidad de películas producidas y conservadas no es constante. Por ejemplo, de acuerdo a David Bordwell, aproximadamente apenas el 20% del cine mudo ha sobrevivido.
- La calidad, apreciación, acceso y exposición a las películas no son uniformes en el tiempo.
- IMDb no está disponible desde 1920 para que los usuarios, tras ver la película estrenada, puedan votarla. Se exige un mínimo de 25.000 votos para que una película entre en la lista.
- IMDb, empresa subsidiaria de Amazon, se centra en los estrenos, trailers y noticias más recientes, no en la evaluación crítica de las películas de la historia del cine.
-
La edad y el perfil de los usuarios que la IMDb considera para elaborar la lista (regular voters).
Otro factor a considerar es el recency effect. Se trata de un sesgo cognitivo que explica que se pondere más, se de más importancia y se recuerde mejor los elementos más recientes.
Referencias:















 Nube de datos
Nube de datos