Problem
We would like to calculate the weighted average in a pivot table in Excel.

Solution
Let's see two alternatives:
- We add a new columng multiplying the variable (mpg) by the weights (disp)
- We create a Calculated Field dividing the new column (mpg*disp) by the weights (disp)
- We create a pivot table adding the Calculated Field.


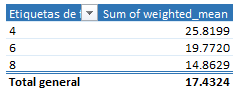
- We add the table to the Data Model.
- We create a new Measure.
- We create a pivot table from Data Model as a data source adding the previous Measure.


weighted_average:=SUMX( Table1,[mpg] * [disp]) / SUM([disp])

Related posts
References














 Nube de datos
Nube de datos