Problema
Queremos añadir interactividad al gráfico creado en la entrada anterior, el gráfico de la derecha de la figura 1.4 del libro An Introduction to Statistical Learning. El gráfico representa el conjunto de datos NCI-60, cada tipo de cáncer con un color y símbolo diferente. Las observaciones que corresponden al mismo tipo de cáncer tienden a estar cerca em este espacio bidimensional.
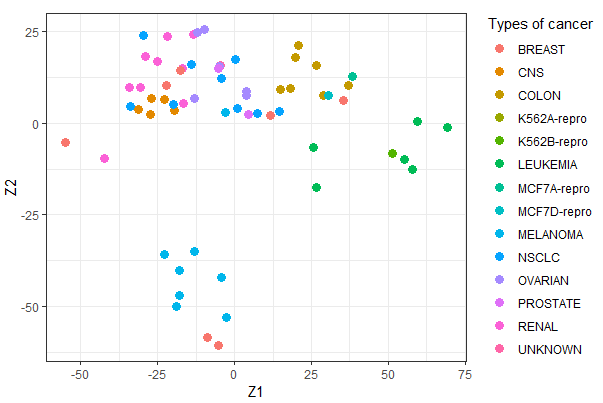
Solución
Empleamos el paquete plotly que permite crear gráficos interactivos en la web. En concreto la función de ggplotly que convierte un objeto ggplot2 en un objeto plotly.
# Librerías y datos NCI60
library(ISLR)
library(tidyverse)
library(plotly)
nci.labs <- NCI60$labs
nci.data <- NCI60$data
pr.out <- prcomp(nci.data, scale = TRUE)
# Gráfico 2
df2 <- data.frame(pr.out$x[, 1:2], nci.labs)
p2 <- ggplot(df2, aes(x = PC1, y = PC2, colour = nci.labs)) +
geom_point(size = 3)+
labs(x = "Z1", y = "Z2")+
theme_bw()+
theme(legend.position="none")
# Interactividad
ggplotly(p2)
Entradas relacionadas
- Gráficos de An Introduction to Statistical Learning con ggplot2 - Figura 1.1
- Gráficos de An Introduction to Statistical Learning con ggplot2 - Figura 1.2
- Gráficos de An Introduction to Statistical Learning con ggplot2 - Figura 1.3
- Gráficos de An Introduction to Statistical Learning con ggplot2 - Figura 1.4
- Entradas de diagramas de dispersión
- Subconjunto de estadísticas descriptivas en R














 Nube de datos
Nube de datos